
FunctionGemma, GPT‑5.2-Codex, Chatterbox Turbo, A2UI, Seedance 1.5 pro, GPT Image 1.5, SAM Audio, Wan2.6, LongCat-Video-Avatar, Mistral OCR 3, Ray3 Modify, FLUX.2 [max] and more
FunctionGemma, GPT‑5.2-Codex, Chatterbox Turbo, A2UI, Seedance 1.5 pro, GPT Image 1.5, SAM Audio, Wan2.6, LongCat-Video-Avatar, Mistral OCR 3, Ray3 Modify, FLUX.2 [max] and more
Hey there! Welcome back to AI Brews - a concise roundup of this week's major developments in AI.
In today’s issue (Issue #118):
AI Pulse: Weekly News at a Glance
Weekly Spotlight: Noteworthy Reads and Open-source Projects
AI Toolbox: Product Picks of the Week
🗞️🗞️ Weekly News at a Glance
Google:
FunctionGemma: a specialized version of Gemma 3 270M model tuned for function calling. It is designed as a strong base for further training into custom, fast, private, local agents that translate natural language into executable API actions [Details].
Gemini 3 Flash: delivers frontier performance on PhD-level reasoning and knowledge benchmarks like GPQA Diamond (90.4%) and Humanity’s Last Exam (33.7% without tools) outperforming Gemini 2.5 Pro, across a number of benchmarks. On SWE-bench Verified, Gemini 3 Flash achieves 78%, outperforming Gemini 3 Pro. It also reaches state-of-the-art performance with 81.2% on MMMU Pro, comparable to Gemini 3 Pro [Details].
T5Gemma 2: the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities [Details].
Data Tables in NotebookLM: synthesizes your sources into clean, structured tables, ready for export to Google Sheets. Available now to Pro and Ultra users and to all users in the upcoming weeks [Details].
A2UI (Agent-to-User Interface): a protocol for Agent-Driven Interfaces. A2UI enables AI agents to generate rich, interactive user interfaces that render natively across web, mobile, and desktop—without executing arbitrary code [Details].
Opal tool for building AI-powered mini apps is now directly available in the Gemini web app as a way to create experimental Gems [Details].
Resemble AI released Chatterbox Turbo, a fast, expressive open source Voice AI model (350M Parameters and 75ms Latency) with built-in watermarking. It supports paralinguistic prompting - text-based tags that tell the model to perform natural vocal reactions in the cloned voice. Supported tags include sigh, gasp, cough and more [Details].

OpenAI:
GPT‑5.2-Codex: a version of GPT‑5.2 further optimized for agentic coding in Codex, including improvements on long-horizon work through context compaction, stronger performance on large code changes like refactors and migrations, improved performance in Windows environments, and significantly stronger cybersecurity capabilities. GPT‑5.2-Codex achieves state-of-the-art performance on SWE-Bench Pro and Terminal-Bench 2.0, benchmarks designed to test agentic performance on a wide variety of tasks in realistic terminal environments [Details].
ChatGPT App Directory launched with app submissions open for review and publication for third-party developers. The app directory is discoverable from the tools menu or directly from chatgpt.com/apps. Developers can use the Apps SDK (in beta) to build chat-native experiences that bring context and action directly into ChatGPT. For now, developers can link out from their ChatGPT apps to their own websites or native apps to complete transactions only for physical goods [Details].
GPT Image 1.5: a major update to their image generation model that now makes precise edits while keeping details intact, improved text rendering and generates images up to 4x faster. GPT Image 1.5 achieves both #1 in Text to Image and Image Editing in the Artificial Analysis Image Arena, surpassing Nano Banana Pro [Details].
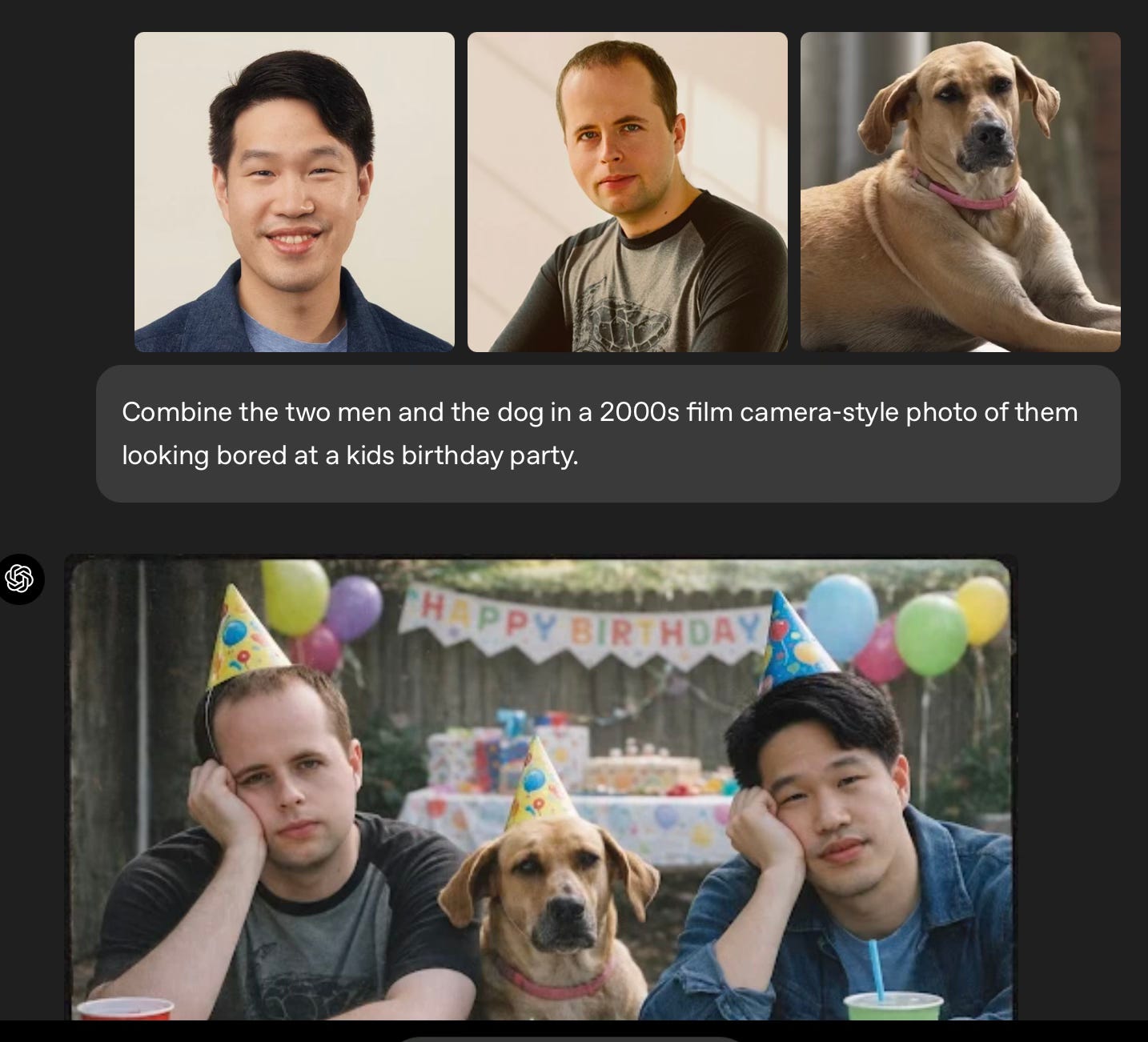
Meta introduced SAM Audio, a unified model that isolates any sound (general sounds, music, and speech) from complex audio mixtures using text, visual, or span prompts. SAM Audio is the first model to introduce span prompting, enabling users to select a specific point in time that contains the target audio for precise separation [Details | Demo].
Tongyi Lab of Alibaba Group released Wan2.6, a native multimodal model for videos and image generation. It can generate up to 15 seconds 1080p HD narrative videos with native synced audio and visuals. It supports reference-based character casting, multi-speaker dialogue with natural lip-sync, and intelligent multi-shot storytelling that converts simple prompts into visually consistent, structured narratives, alongside image synthesis and editing with precise aesthetic control [Details].
Bytedance unveiled Seedance 1.5 pro, a joint audio-video model that accurately follows complex instructions. It can generate diverse voices and spatial sound effects that coordinate with the visuals and supports lip-sync, dynamic camera movement, and cinematic detail from close-ups to full shots [Details].
Claude Code now has a first-party plugins marketplace, making it easier to discover and install popular plugins. Run /plugins to browse and batch install available plugins from the directory. You can install plugins at user, project, or local scope [Details].
Apple released SHARP, a model that synthesizes a photorealistic 3D representation from a single photograph in less than a second. The synthesized representation supports high-resolution rendering of nearby views, with sharp details and fine structures, at more than 100 frames per second on a standard GPU [Details].
Meituan released LongCat-Video-Avatar, an open-source unified model that delivers expressive and highly dynamic audio-driven character animation, supporting native tasks including Audio-Text-to-Video, Audio-Text-Image-to-Video, and Video Continuation with seamless compatibility for both single-stream and multi-stream audio inputs [Details].
Mistral AI introduced Mistral OCR 3 model - 74% overall win rate over Mistral OCR 2 on forms, scanned documents, complex tables, and handwriting. Available via the API and in the new Document AI Playground interface, both in Mistral AI Studio [Details].
Letta launched Letta Code, a memory-first, open-source coding agent that persists across sessions, allowing agents to learn and improve over time rather than operating in isolated interactions. It is the #1 model-agnostic OSS harness on TerminalBench, and achieves comparable performance to Claude Code, Gemini CLI and Codex CLI when paired with their respective models [Details].
NVIDIA:
Nemotron 3 family of open models: includes Nemotron 3 Nano (30B parameters, 3B active), Nemotron 3 Super (100B parameters, 10B active) and Nemotron 3 Ultra( 500B parameters, 50B active). Nemotron 3 Nano is available today; Nemotron 3 Super and Ultra are expected to be available in the first half of 2026.
NeMo Gym and NeMo RL: open-source libraries which provide the training environments and post-training foundation for Nemotron models, along with NeMo Evaluator to validate model safety and performance [Details]
Luma Labs introduced Ray3 Modify, a new video editing model in Dream Machine that lets creators precisely edit and reimagine footage with start/end keyframe control and character reference features while preserving original performance, motion, and narrative continuity [Details]
xAI launched the Grok Voice Agent API for developers to build voice agents that speak dozens of languages, call tools, and search realtime data. It ranks #1 on Big Bench Audio, the audio reasoning benchmark that measures voice agents’ capabilities to solve complex problems [Details].
Black Forest Labs released FLUX.2 [max], their highest-quality image model yet, featuring grounded generation with real-time web context, support for up to 10 reference images, and a #2 ranking in text-to-image and image editing on Artificial Analysis [Details].
Exa AI launched People Search - you can now semantically search over 1 billion people using a hybrid retrieval system backed by finetuned Exa embeddings [Details].
Anthropic is launching Agent Skills as an independent open standard with a specification and reference SDK available at https://agentskills.io [Details].
A2I released Olmo 3.1, extending the original Olmo 3 models with longer and more effective post-training reinforcement learning to substantially improve reasoning, math, and instruction-following performance at the 32B scale. This release includes Olmo 3.1 Think 32B and Olmo 3.1 Instruct 32B [Details].


🔦 🔍 Weekly Spotlight
Articles/Courses/Videos:
Agentic design patterns: The missing link between AI demos and enterprise value
Build with Google’s new A2UI Spec: Agent User Interfaces with A2UI + AG-UI
Open-Source Projects:
Claude-mem: A Claude Code plugin that automatically captures everything Claude does during your coding sessions, compresses it with AI (using Claude’s agent-sdk), and injects relevant context back into future sessions.
HyperbookLM: A powerful research assistant built with Next.js 15, React 19, and Hyperbrowser. It allows users to aggregate diverse sources (Web URLs, PDFs) and gain deep insights through interactive AI tools.
🔍 🛠️ Product Picks of the Week
Code Wiki by Google: an AI-powered documentation hub for a code repository. A specialized AI agent uses Gemini to analyze source code and generate all the content in the wiki including architectural diagrams.
Sim: Open-source visual workflow builder for building and deploying AI agent workflows.
Ngrok.ai: One gateway for every AI model. Route, secure, and manage traffic to any LLM, cloud or local, with one unified platform.
Last Issue
GPT‑5.2, GLM-4.6V, Runway's GWM Worlds, GWM Avatars and GWM Robotics, Nomos 1, Devstral 2, Wan-Move, SimGym, Disco, Stripe's Agentic Commerce Suite and more
Hey there! Welcome back to AI Brews - a concise roundup of this week's major developments in AI.

Thanks for reading and have a nice weekend! 🎉 Mariam.
Seedance 1.5 pro's spatial sound coordination with visuals is notable since most audio-video models stil treat audio as an afterthought or separate generation step. The ability to generate sound effects that spatially correspond to onscreen action (not just temporal sync) suggests they're modeling acoustic properties alongside visual composition. SAM Audio's span prompting is clever too, letting you point at a moment to isolate specific sounds rather than trying to describe them textualy. The convergence toward native multimodal generation (Wan2.6, Seedance) where audio and visual aren't bolted together post-hoc will probaly shift how people think about content creation workflows.
Exa AI's People Search: What a perfectly non-creepy concept, nothing to see here!