
Cogito v2, GLM-4.5 , first open-source MoE Video Model, fully autonomous ML agent, FLUX.1 Krea [dev], Qwen3-Coder-Flash, Manus Wide Research, Runway Aleph, Intern-S1, Step3, Action Agent & more
Cogito v2, GLM-4.5 , first open-source MoE Video Model, fully autonomous ML agent, FLUX.1 Krea [dev], Qwen3-Coder-Flash, Manus Wide Research, Runway Aleph, Intern-S1, Step3, Action Agent & more
Hey there! Welcome back to AI Brews - a concise roundup of this week's major developments in AI.
In today’s issue (Issue #108):
AI Pulse: Weekly News at a Glance
Weekly Spotlight: Noteworthy Reads and Open-source Projects
AI Toolbox: Product Picks of the Week
From our sponsors:
Make sense of what matters in AI in minutes —minus the clutter

There’s so much AI hype going around, it’s overwhelming to keep up.
… And that’s assuming you’re following the stuff that actually matters.
Fortunately, there's The Deep View, a newsletter that sifts through all the AI-related noise for you.
It gives you 5-minute insights on what truly matters right now in AI, and it’s trusted by over 452,000 subscribers, including executives at Microsoft, Scale, and Coinbase.
Sign up now for free and start making smarter decisions in the AI space.
🗞️🗞️ Weekly News at a Glance
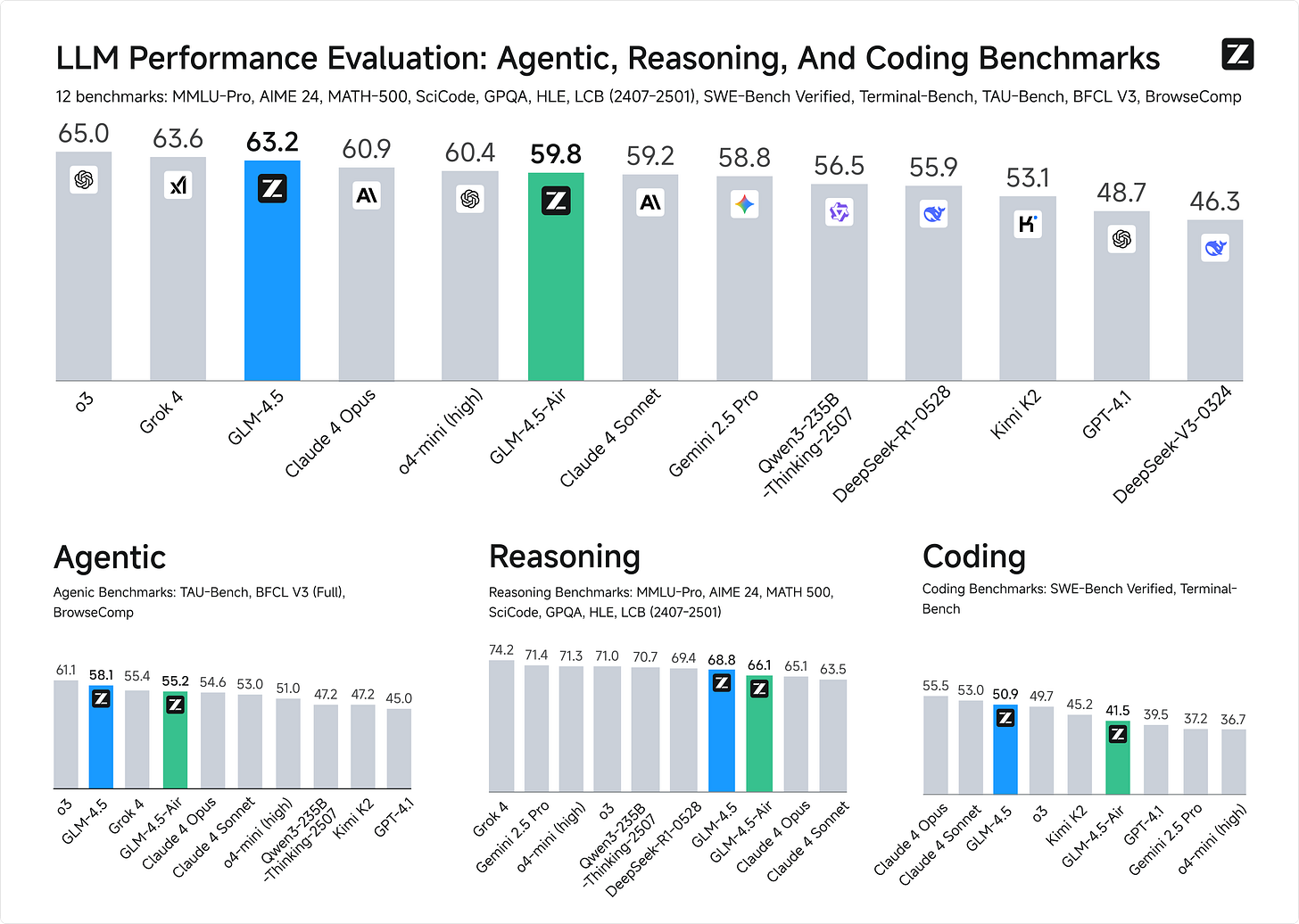
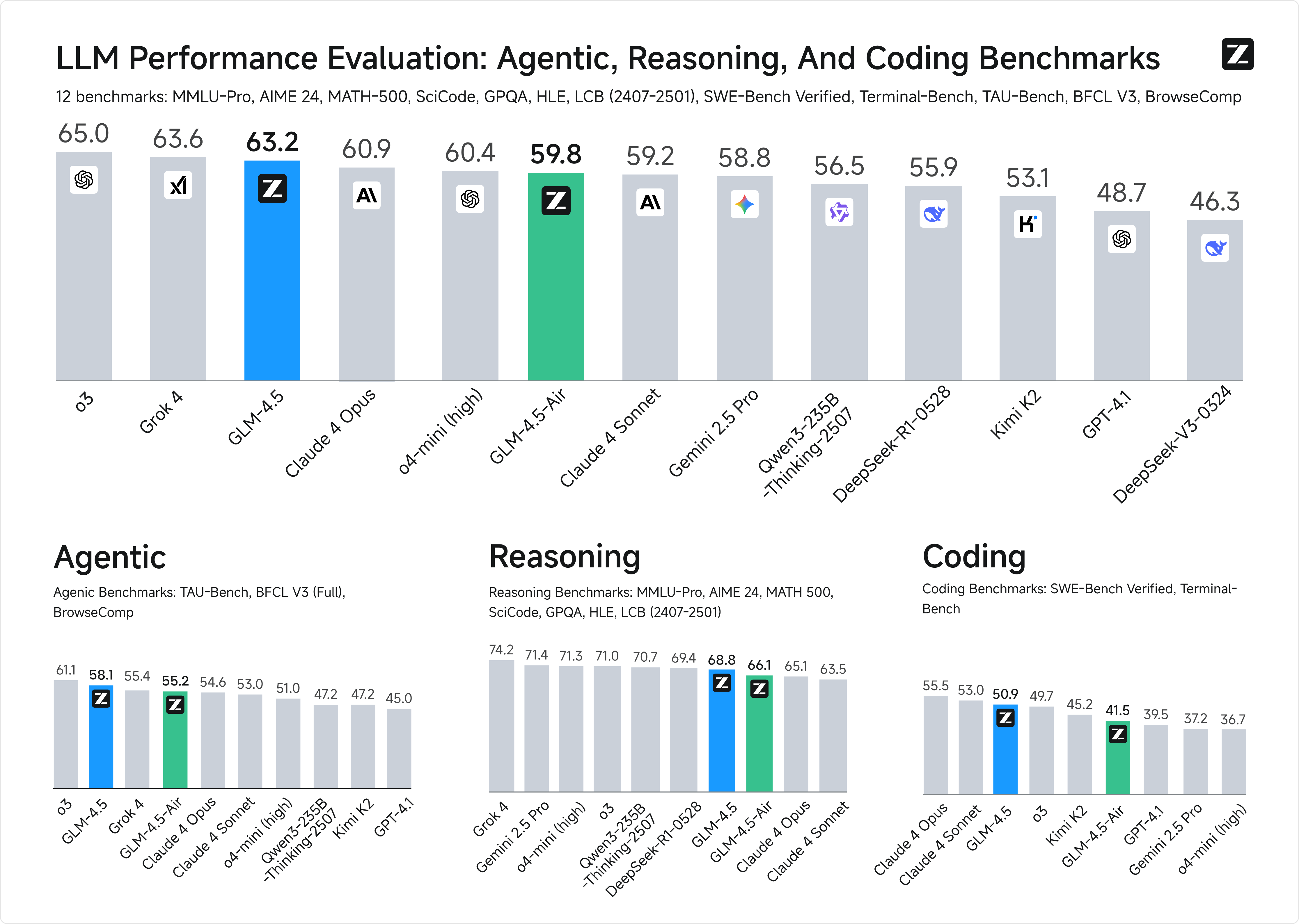
Z.ai (formerly Zhipu) released GLM-4.5 and GLM-4.5-Air open-weights hybrid reasoning models designed for intelligent agents. GLM-4.5 is built with 355 billion total parameters and 32 billion active parameters, and GLM-4.5-Air with 106 billion total parameters and 12 billion active parameters. Both are designed to unify reasoning, coding, and agentic capabilities into a single model. In an evaluation across 12 industry-standard benchmarks, GLM-4.5 achieved a score of 63.2, in the 3rd place among all the proprietary and open-source models [Details].
Deep Cogito released 4 hybrid reasoning models of sizes 70B, 109B MoE, 405B, 671B MoE under open license. Cogito v2 models serve as a proof of concept for a novel AI paradigm - iterative self-improvement (AI systems improving themselves). The largest 671B MoE model matches/exceeds the performance of the latest DeepSeek v3 and DeepSeek R1 models and approaches closed frontier models like o3 and Claude 4 Opus [Details].
Tongyi Lab of Alibaba Group released Wan2.2, an open-source video generation model with cinematic control. Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos [Details].
Alibaba Qwen released a small-sized Qwen3-Coder model: Qwen3-Coder-Flash ( Qwen3-Coder-30B-A3B-Instruct) optimized for platforms like Qwen Code, Cline, Roo Code, Kilo Code, etc. Last week Qwen released Qwen3-Coder-480B-A35B-Instruct, their most powerful open agentic code model - 480B-parameter Mixture-of-Experts model (35B active) that natively supports 256K context and scales to 1M context with extrapolation that sets new state-of-the-art results among open models on Agentic Coding, Agentic Browser-Use, and Agentic Tool-Use, comparable to Claude Sonnet 4 [Details].
Runway introduced Runway Aleph, a state-of-the-art in-context video model, with the ability to perform a wide range of edits on an input video such as adding, removing, and transforming objects, generating any angle of a scene, and modifying style and lighting, among many other tasks [Details].
Manus AI is rolling out a new feature called Wide Research, a system-level mechanism for parallel processing, and a protocol for agent-to-agent collaboration. It lets you explore multiple questions, comparisons, or deep dives in parallel, without switching tabs or losing structure. Unlike traditional multi-agent systems based on predefined roles (like "manager", "coder", or "designer"), every subagent in Wide Research is a fully capable, general-purpose Manus instance [Details].
StepFun released Step3, an open-source multimodal reasoning model built on a Mixture-of-Experts architecture with 321B total parameters and 38B active. It is designed end-to-end to minimize decoding costs while delivering top-tier performance in vision–language reasoning [Details].
Tencent released Hunyuan3D World Model 1.0, an open-source model to generate immersive, explorable, and interactive 3D worlds from just a sentence or an image [Details].
InternLM released Intern-S1, an open-source multimodal reasoning model that combines strong general-task capabilities with state-of-the-art performance on a wide range of scientific tasks, rivalling leading closed-source commercial models. Built upon a 235B MoE language model (Qwen3) and a 6B Vision encoder (InternViT), Intern-S1 has been further pretrained on 5 trillion tokensof multimodal data, including over 2.5 trillion scientific-domain tokens [Details].
Google DeepMind introduced AlphaEarth Foundations, an AI model that integrates petabytes of satellite data into a single digital representation of Earth and functions like a virtual satellite. It'll give scientists a nearly real-time view of the planet to incredible spatial precision, and help with critical issues like food security, deforestation & water resources [Details].
Black Forest Labs released FLUX.1 Krea [dev], developed in collaboration with Krea AI. FLUX.1 Krea [dev] is a new state-of-the-art open-weights model for text-to-image generation that overcomes the oversaturated 'AI look' to achieve new levels of photorealism with its distinctive aesthetic approach [Details].
![Krea [dev] Images sample](https://substackcdn.com/image/fetch/$s_!bTBz!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F29f89d2f-7358-40c4-9319-d9f648da08dd_3072x2560.jpeg "Krea [dev] Images sample")
Microsoft launched Copilot Mode, a new experimental mode in Microsoft Edge browser which allows you to browse the web while being assisted by AI and perform actions like booking reservations or managing errands on your behalf. . The Copilot can see all your open tabs with full context of what you’re exploring online and supports natural voice navigation [Details].
Cohere introduced Command A Vision, a new state-of-the-art generative model that excels across enterprise image understanding tasks while keeping a low compute footprint. It surpasses other models in its class including GPT 4.1, Llama 4 Maverick, Mistral Medium 3 (and Pixtral Large) on key multimodal benchmarks [Details].
Google is rolling out Video Overviews and new upgrades to the Studio panel in NotebookLM app. Video Overviews are a visual alternative to Audio Overviews: the AI host creates new visuals to help illustrate points while also pulling in images, diagrams, quotes and numbers from your documents [Details].
Neo AI introduced NEO, an agentic Machine Learning engineer. Powered by 11 specialized agents, NEO runs autonomously handling data exploration, feature engineering, training, tuning, deployment, and monitoring, end to end [Details].
WRITER launched Action Agent, a general-purpose autonomous agent purpose-built for the enterprise. It’s powered by Palmyra X5, WRITER’s latest adaptive reasoning LLM and outperforms Manus and OpenAI Deep Research on the most difficult level of the General AI Assistants (GAIA) benchmark [Details].
Mistral unveiled the complete Mistral Coding Stack for enterprise and Codestral 25.08. The Mistral coding stack integrates autocomplete, semantic retrieval, and agentic workflows directly into the IDE—while giving platform teams control over deployment, observability, and security [Details].
Claude Code now supports creation and use of specialized AI subagents for task-specific workflows and improved context management. When Claude Code encounters a task that matches a subagent’s expertise, it can delegate that task to the specialized subagent, which works independently and returns results [Details].
Google announced Opal, a new experimental tool from Google Labs that lets you build and share powerful AI mini apps that chain together prompts, models, and tools — all using simple natural language and visual editing [Details].
Ideogram introduced Ideogram Character, a character consistency model that works with just one reference image [Details].

OpenAI added a study mode in ChatGPT, a learning experience that helps you work through problems step by step instead of just getting an answer. It’s available to logged in users on Free, Plus, Pro and Team, with availability in ChatGPT Edu coming in the next few weeks [Details],
Morphic launched a new 3D Motion feature that turns any image into a 3D motion video on Morphic [Details].
![Krea [dev] Images sample](https://substackcdn.com/image/fetch/$s_!bTBz!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F29f89d2f-7358-40c4-9319-d9f648da08dd_3072x2560.jpeg "Krea [dev] Images sample")

🔦 🔍 Weekly Spotlight
Articles/Courses/Videos:
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Context Engineering for AI Agents: Lessons from Building Manus
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
Open-Source Projects:
Eigent: Multi-agent workforce desktop application, empowering you to build, manage, and deploy a custom AI workforce that can turn your most complex workflows into automated tasks.
Flow Maker by LlamaIndex: tool for visually creating and exporting agentic workflows powered by LlamaIndex. It provides a drag-and-drop interface to build complex workflows, run them interactively, and then compile them into standalone TypeScript code
mini-SWE-agent: The 100 line AI agent that solves GitHub issues or helps you in your command line
🔍 🛠️ Product Picks of the Week
GitHub Spark: Create full-stack applications with built-in AI, using natural language, visual tools, or code.
Lumo by Proton: A privacy-first AI assistant that’s based upon open-source language models and operates from Proton’s European datacenters.
Browser Use Search API: Crawls sites and fetches real-time data by interacting with any website.
Kiro: A new agentic IDE that works alongside you from prototype to production
Higgsfield Reference Chrome Extension: Select any image from the web and, with one click, generate a similar visual - no prompt needed.
Composite: Composite clicks, types, and navigates on your behalf. Works on any website. Connects to your existing browser.
Thanks for reading and have a nice weekend! 🎉 Mariam.