


Qwen2, Kling video model, Text to Sound Effects, No Language Left Behind model, video gaming AI assistant, Audio uploads and more
Qwen2, Kling video model, Text to Sound Effects, No Language Left Behind model, video gaming AI assistant, Audio uploads and more
Hi. Welcome to this week's AI Brews for a concise roundup of the week's major developments in AI.
In today’s issue (Issue #66 ):
AI Pulse: Weekly News & Insights at a Glance
AI Toolbox: Product Picks of the Week
🗞️🗞️ AI Pulse: Weekly News & Insights at a Glance
🔥 News
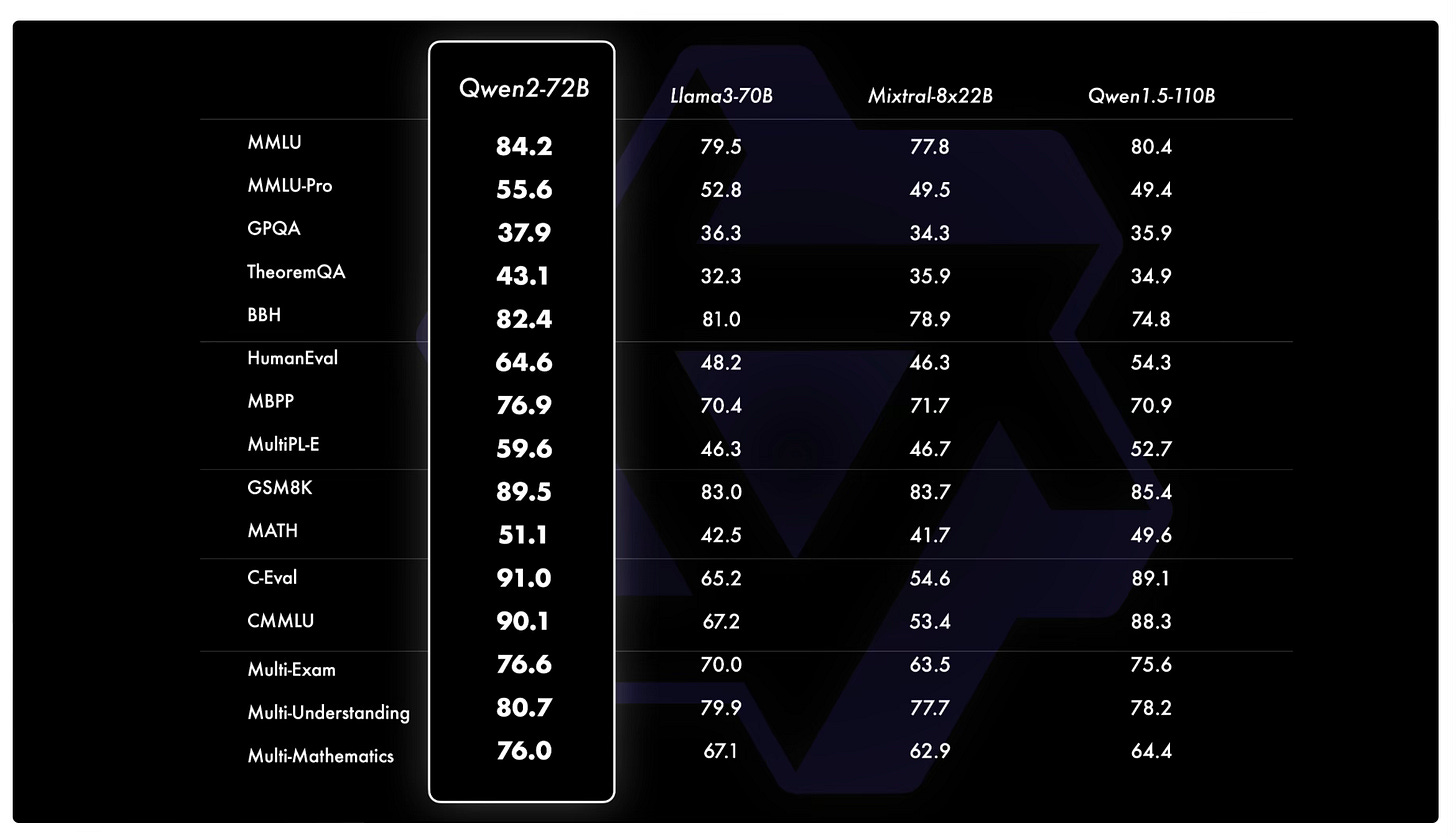
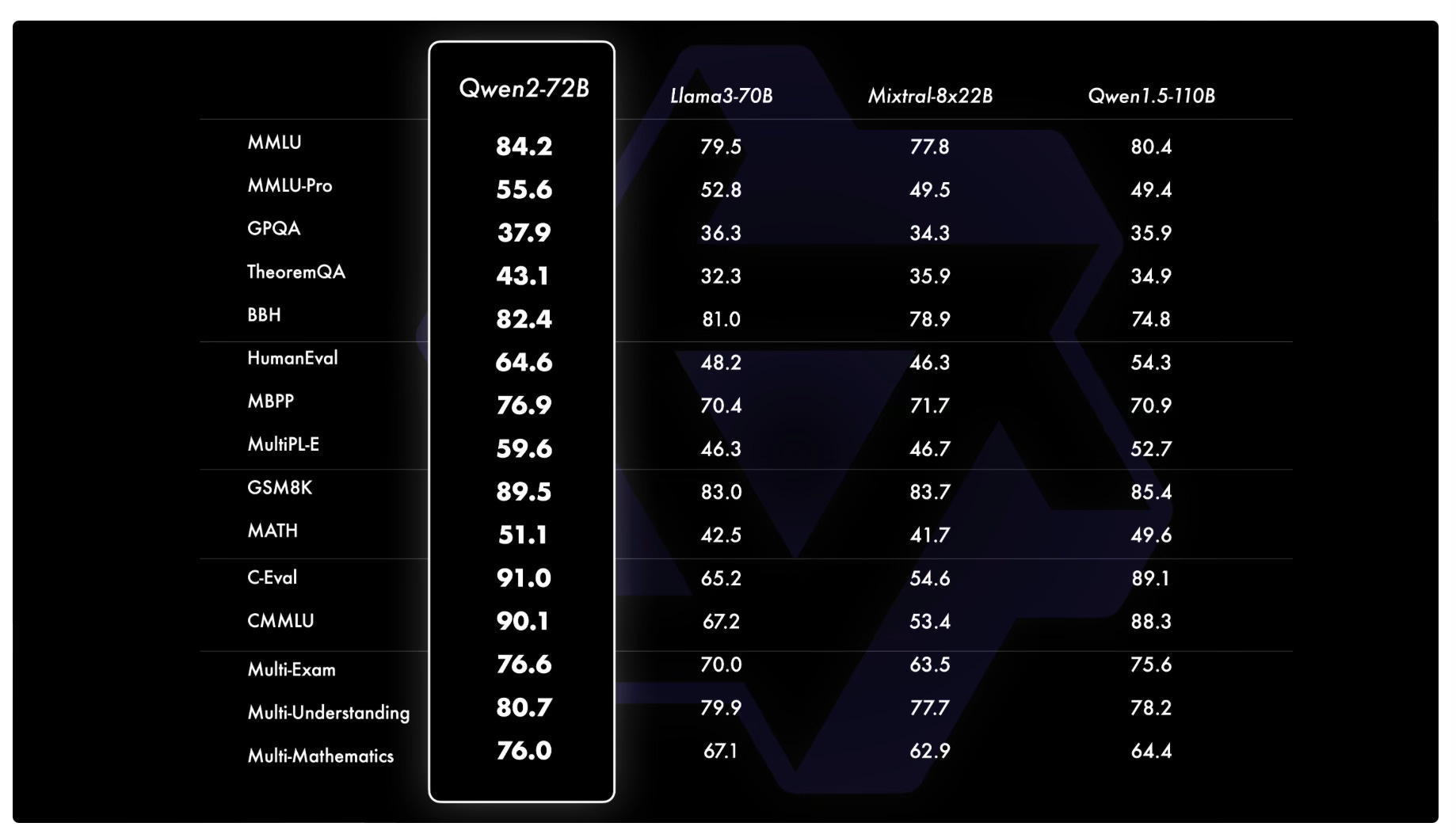
Alibaba Cloud released Qwen2 series of open models in 5 sizes: 0.5B, 1.5B, 7B, 57B-14B (MoE), 72B trained on data in 29 languages. Qwen2-72B outperforms Llama-3-70B and surpasses the performance of its predecessor, Qwen1.5-110B, despite having fewer parameters. Released under Apache 2.0 except 72B version that still uses the original Qianwen License [Details].
China’s Kuaishou Technology unveiled its text-to-video model Kling that can generate 1080p high-definition videos lasting up to 2 minutes. The model is capable of producing large-scale realistic motions and simulating physical world characteristics [Details | Demo videos].
Stability AI released Stable Audio Open, an open source text-to-audio model for generating up to 47 seconds of audio samples and sound effects. It can generate drum beats, instrument riffs, ambient sounds, foley recordings and other audio samples for music production and sound design [Details].
Researchers have used AI to identify nearly one million potential antibiotic compounds from microbial genetic data, marking a significant breakthrough in combating drug-resistant superbugs. Discovering a new antibiotic using conventional methods typically takes about 10 to 15 years [Details].
Udio has added ‘audio uploads’, a new experimental feature to their AI music generation tool. You can upload an audio clip of your choice, and extend this clip either forward or backward by 32 seconds using up to 2 minutes of context [Details].
Two authors of the Stanford Llama3-V team apologized to the Chinese team behind the MiniCPM-Llama3-V 2.5 open-source model, announcing they would withdraw the Llama3-V model from use amidst allegations of plagiarism on social media [Details].
Nvidia shared demo of Project G-Assist - an RTX-powered AI assistant that provides context-aware help for PC games and apps. In addition to in-game assistance, it can share useful system information, configure settings to increase performance and power efficiency, and more [Video Link].
Meta AI researchers introduced No Language Left Behind (NLLB), a single massively multilingual model capable of delivering high-quality translations directly between 200 languages, including the low-resource languages [Details].
Nomic AI released Nomic-Embed-Vision, an open vision embedding model. Any vector created using Nomic-Embed-Text can be used to query vectors created by Nomic-Embed-Vision, and vice versa. The unified multimodal latent space outperforms the modality specific latent spaces of models like OpenAI Clip and OpenAI Text Embedding 3 Small, and making it the first open weights model to do so [Details].
Mistral AI announced Mistral AI fine-tuning API as well as an open-source fine-tuning SDK for Mistral models [Details].
Eleven Labs launched Text to Sound Effects tool. Their new AI Audio model can generate sound effects, short instrumental tracks and soundscapes from a text prompt [Details].
Artificial Analysis launched Artificial Analysis Text to Image Model Leaderboard, to compare the quality of image models. You can take part in the Text to Image Arena, and get your personalized model ranking after 30 votes [Details]
SkyworkAI released Skywork-MoE, a mixture-of-experts (MoE) model with 146 billion parameters, 16 experts, and 22 billion activated parameters. This model is initialized from the pre-existing dense Skywork-13B model. Skywork-MoE shows comparable or superior performance to models with more parameters or more activated parameters, such as Grok-1, DBRX, Mistral 8*22, and Deepseek-V2 [Details].
Nvidia and Hugging Face are partnering to simplify generative AI model deployments. The dedicated NIM endpoint spins up cloud instances, fetches Nvidia-optimized models, and enables inference with just a few clicks [Details].
Firefox 130 will introduce an experimental new capability to automatically generate alt-text for images using a fully private on-device AI model. The feature will be available as part of Firefox’s built-in PDF editor [Details].
Microsoft Research introduced Aurora, a large-scale foundation model of the atmosphere trained on over a million hours of diverse weather and climate data. In under a minute, Aurora produces 5-day global air pollution predictions and 10-day high-resolution weather forecasts that outperform state-of-the-art classical simulation tools and the best specialized deep learning models [Details].
Stability AI officially announced the open release date of Stable Diffusion 3 Medium for June 12th. Signup for the wait list here [Link].
OpenAI shared their research work towards understanding the neural activity of language models and released a full suite of autoencoders for GPT-2 small, along with code for using them, and the feature visualizer to get a sense of what the GPT-2 and GPT-4 features may correspond to [Details]
Together AI released Dragonfly, a set of vision-language models based on a new architecture that enhances fine-grained visual understanding and reasoning about image regions. Two new open-source models released: Llama-3-8b-Dragonfly-v1 a general-domain model trained on 5.5 million image-instruction pairs and Llama-3-8b-Dragonfly-Med-v1 finetuned on additional 1.4 biomedical image-instruction data [Details].
Mamba 2, the next version of Mamba state space model has been released. Researchers shared the new architecture details in a blog post [GitHub].
Mozilla has launched the 2024 Builders Accelerator offering up to $100,000 in funding for projects that advance open source AI, with a focus on Local AI solutions [Details].
Current and former employees of major AI companies have published an open letter ‘A Right to Warn about Advanced Artificial Intelligence’, advocating for stronger protections and transparency measures to enable safe disclosure of AI-related risks without fear of retaliation [Details]
Google updated its AI Overviews in Search, addressing issues with erroneous and fake information [Details].
Amazon’s Project PI, or ‘Private Investigator,’ setup combines generative AI and computer vision to ‘see’ damage on products or determine if they are the wrong color or size before the item gets sent to customers [Details].
Nvidia CEO Jensen Huang introduced the company's next-generation AI-accelerating GPU platform, “Rubin“ expected in 2026 [Details].
🔦 Weekly Spotlight
Situational Awareness - The Decade Ahead by Leopold Aschenbrenner, former OpenAI researcher on AGI [Link].
ToonCrafter: Generative Cartoon Interpolation [Link].
The Rise of AI Agent Infrastructure by Madrona [Link].
What We Learned from a Year of Building with LLMs (Part II) [Link].
NPC-Playground, a 3D playground to interact with LLM-powered NPCs [Link].
This Hacker Tool Extracts All the Data Collected by Windows’ New Recall AI [Link].
Qwen-Agent: Agent framework and applications built upon Qwen2, featuring Function Calling, Code Interpreter, RAG, and Chrome extension[Link].
An entirely open-source AI code assistant inside your editor - uses Continue and Ollama [Link].
FineWeb dataset technical report [Link].
Groqbook, an open-source streamlit app for the creation of books from a one-line prompt using Llama3 on Groq [Link].
🔍 🛠️ AI Toolbox: Product Picks of the Week
Databutton: Describe your app in natural language, screenshots, or diagrams and Databutton generates the necessary React frontend and Python backend code.
Gumloop: Automate any workflow with AI, without coding.
TurboSeek: An open source AI search engine by Together.ai.
HourOne: AI video creation platform with AI avatars
Last week’s issue
Netflix of AI, Perplexity Pages, AI agent platform for financial analysis, Low-latency voice model, AI Prize Fight, Codestral, K2 and MAP-Neo models, AutoCoder, HuggingChat Tools and more
Hi. Welcome to this week's AI Brews for a concise roundup of the week's major developments in AI. In today’s issue (Issue #65 ): AI Pulse: Weekly News & Insights at a Glance AI Toolbox: Product Picks of the Week

You can support my work via BuyMeaCoffee.
Thanks for reading and have a nice weekend! 🎉 Mariam.