


Claude 3.5 and Artifacts, Florence-2 and Meta's models, Expressive talking and singing characters, Video to Sounds Effects app, DeepSeek-Coder-V2, video-to-audio and more
Claude 3.5 and Artifacts, Florence-2 and Meta's models, Expressive talking and singing characters, Video to Sounds Effects app, DeepSeek-Coder-V2, video-to-audio and more
Hi. Welcome to this week's AI Brews for a concise roundup of the week's major developments in AI.
In today’s issue (Issue #68 ):
AI Pulse: Weekly News & Insights at a Glance
AI Toolbox: Product Picks of the Week
🗞️🗞️ AI Pulse: Weekly News & Insights at a Glance
🔥 News
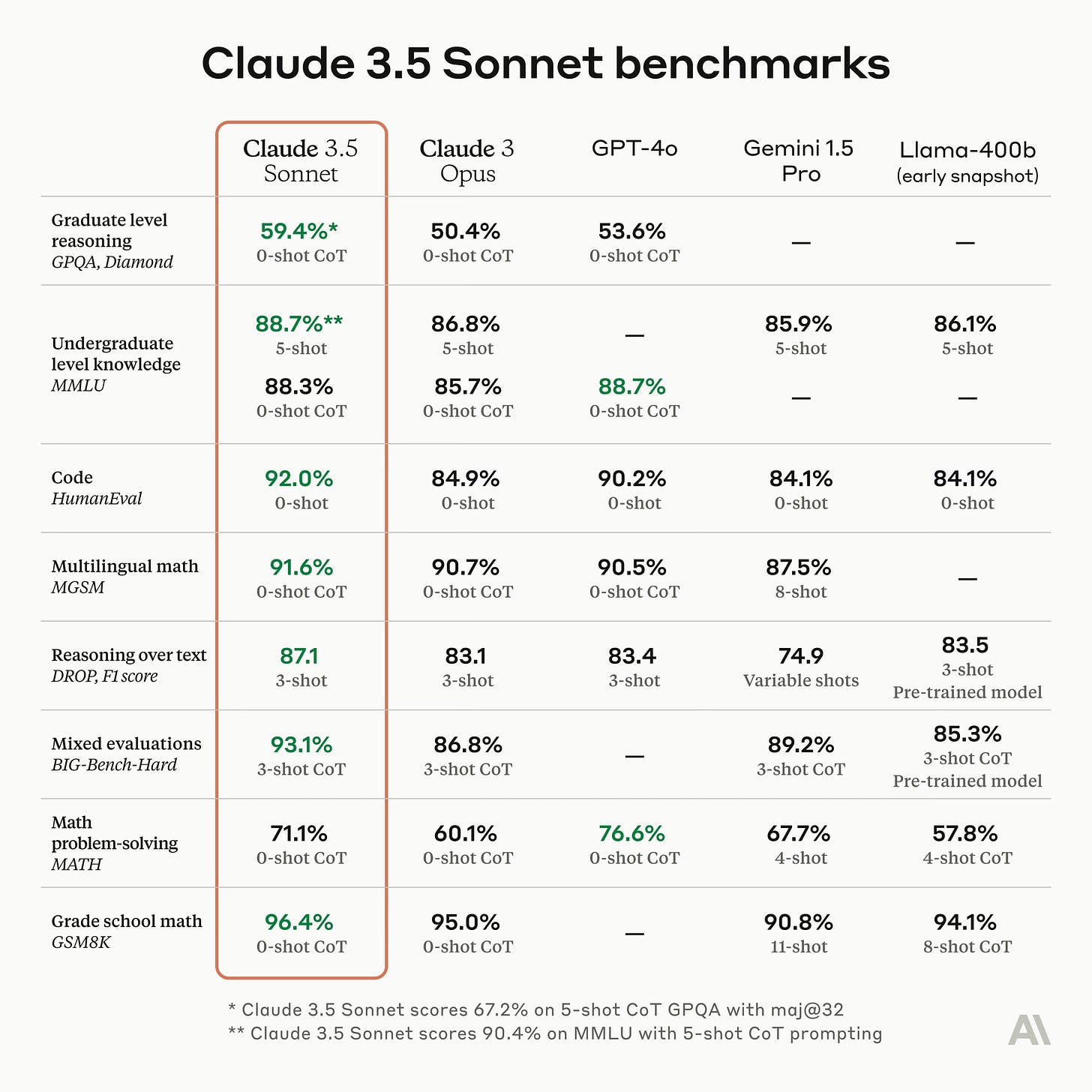
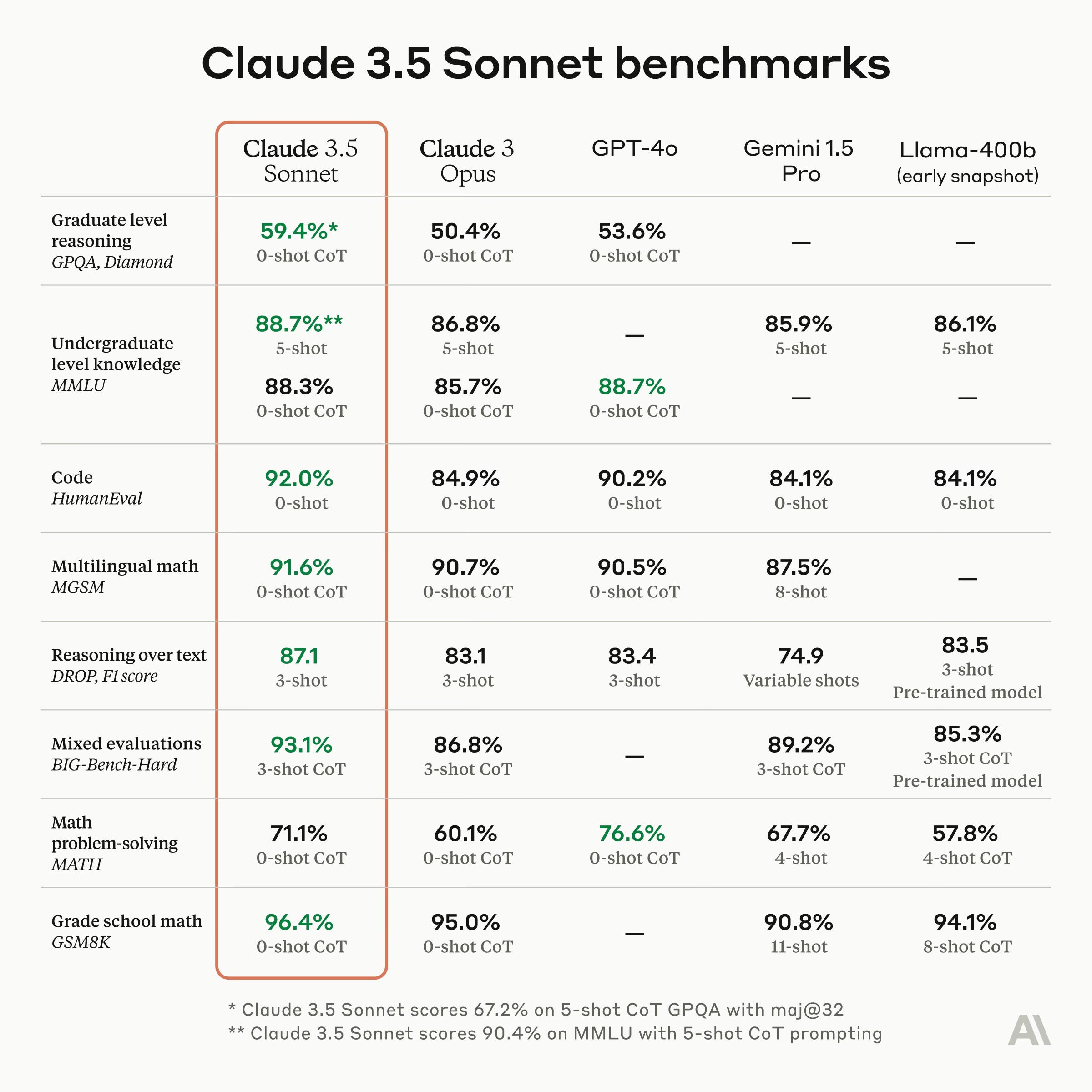
Anthropic launches Claude 3.5 Sonnet, the first release in the 3.5 model family. Sonnet now outperforms competitor models like GPT-4o and Gemini 1.5 Pro on key evaluations. It is 2x faster and 5x cheaper than Claude 3 Opus. Claude 3.5 Sonnet shows marked improvement in grasping nuance, humor, and complex instructions, all while writing with a natural tone. Sonnet surpasses Claude 3 Opus across all standard vision benchmarks. It is available for free on claude.ai and the iOS app. Claude 3.5 Haiku and Claude 3.5 Opus will be available later this year. Anthropic also launched Artifacts, a feature enabling users to interact, edit, and build upon AI-generated content in real-time [Details]
Microsoft released Florence-2, small tiny vision foundation model (0.23B and 0.77B) that can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. Florence-2 0.23B outperforms much larger model Flamingo-80B in Zero-Shot [Details].
Meta’s Fundamental AI Research (FAIR) team announced the release of four new publicly available AI models and additional research artifacts [Details]:
Meta Chameleon 7B & 34B language models that support mixed-modal input and text-only outputs.
Meta JASCO generative text-to-music model. Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation (JASCO), is capable of accepting various conditioning inputs, such as specific chords or beats, to improve control over generated music outputs. Paper available today with a pretrained model coming soon.
Meta Multi-Token Prediction Pretrained Language Models for code completion using Multi-Token Prediction. Using this approach, language models are trained to predict multiple future words at once—instead of the old one-at-a-time approach
Meta AudioSeal An audio watermarking model that designed specifically for the localized detection of AI-generated speech, available under a commercial license.
Nvidia announced Nemotron-4 340B, a family of open models that developers can use to generate synthetic data for training large language models (LLMs) for commercial applications [Details | Hugging Face].
DeepSeek AI released DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. DeepSeek-Coder- V2 236B outperforms state-of-the-art closed-source models, such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro, in both coding and mathematics tasks [Details].
Google DeepMind is developing video-to-audio (V2A) generative technology. It uses video pixels and text prompts to add sound to silent clips that match the acoustics of the scene, V2A technology is pairable with video generation models like Veo to create shots with a dramatic score, realistic sound effects or dialogue that matches the characters and tone of a video [Details].
Runway introduced Gen-3 Alpha, a new model for video generation trained jointly on videos and images. Gen-3 Alpha can create highly detailed videos with complex scene changes, a wide range of cinematic choices and detailed art directions. It excels at generating expressive human characters with a wide range of actions, gestures, and emotions. It’s not publicly available yet [Details].
Apple released 20 new CoreML models for on-device AI and 4 new datasets on Hugging Face [Details].
Google Research has built an AI-powered tool SurfPerch that can automatically process thousands of hours of audio to build new understanding of coral reef ecosystems [Details].
Fireworks released Firefunction-v2 - an open weights function calling model that is competitive with GPT-4o function calling capabilities. It’s available at a fraction of the cost of GPT-4o ($0.9 per output token vs $15) and with better latency [Details].
ElevenLabs text to sound effects API is now live. ElevenLabs also released a Video to Sounds Effects app which is open-source and free online.
Code Droid, an AI agent by Factory to execute coding tasks based on natural language instructions achieves state-of-the-art performance on SWE-bench, a benchmark to test an AI system’s ability to solve real-world software engineering tasks [Details].
Wayne introduced PRISM-1, a scene reconstruction model of 4D scenes (3D in space + time) from video data [Details].
Roblox is building toward 4D generative AI, going beyond single 3D objects to dynamic interactions [Details].
TikTok is expanding its Symphony ad suite with AI dubbing tools and avatars based on paid actors and creators [Details].
Ilya Sutskever, one of OpenAI’s co-founders, has launched a new company, Safe Superintelligence Inc. (SSI) one month after formally leaving OpenAI [Details].
Anthropic is offering a limited access to Anthropic's Beta Steering API. It is for experimentation only and will allow developers to adjust internal features of Anthropic’s language models [Details].
Snap previews its real-time on-device image diffusion model that can generate AR experiences [Details].
Open Interpreter's Local III update includes an easy-to-use local model explorer, deep integrations with inference engines like ollama and a free language model endpoint serving Llama3-70B [Details].
🔦 Weekly Spotlight
AI in Finance - Bot, Bank & Beyond - report by Citi GPS [Link].
Melody Agents: When crewAI meets Suno AI - This repository contains a crewAI application for automatically generating songs given a topic and a musc genre [Link].
State of AI report by Retool [Link].
Introducing AutoGen Studio: A low-code interface for building multi-agent workflows [Link]
Optimizing AI Inference at Character.AI [Link]
🔍 🛠️ AI Toolbox: Product Picks of the Week
Hedra: Generate video with expressive and controllable human characters that can talk and sing, powered by Hedra’s Character-1 foundation model
Vizly: use AI to explore your data and create interactive visualizations using natural language.
Butterflies: AI social networking app where humans and AI coexist and interact through posts, comments and DMs.
Last week’s issue
Dream Machine, Apple Intelligence, AI to understand animals communication, Mixture of Agents, Real-time Expressive Generative Humans, Skybox AI new model and more
Hi. Welcome to this week's AI Brews for a concise roundup of the week's major developments in AI. In today’s issue (Issue #67 ): AI Pulse: Weekly News & Insights at a Glance AI Toolbox: Product Picks of the Week Advertise in this newsletter to reach over 9,000 AI engineers, founders, and enthusiasts with your message.

You can support my work via BuyMeaCoffee.
Thanks for reading and have a nice weekend! 🎉 Mariam.